

 +44-7511-112566
+44-7511-112566 +353-1-8079571
+353-1-8079571 +1-415-799-9792
+1-415-799-9792

Machine learning (ML) with Artificial Intelligence has an excellent capacity to do anything. They can analyze X-rays, forecast stock market prices, and suggest television programs that viewers should binge-watch. With such a broad spectrum of applications, the worldwide machine-learning industry is expected to increase from $21.7 billion in 2022 to $209.91 billion by 2029. Algorithms, which are trained to create the machine learning models that power some of the most significant advancements in the world today, are at the heart of machine learning. So, let’s read the blog to know the top ten machine learning algorithms.
What advantages do machine learning algorithms offer?
The advantages of utilising machine learning algorithms are as follows.
- The machine learning algorithms are used in practically every industry that exists, including banking, healthcare, publishing, retail, and more.
- Users are shown targeted adverts based on their preferences, needs, and search patterns and behaviours.
- offers the ability to handle complex and variable data requirements in even the most dynamic circumstances.
- reduces time cycle and offers efficient resource use.
- offers opportunities to enhance processes and quality through its ongoing feedback system.
- Based on the feedback produced in different other systems, it is possible to automate some processes.
Types Of Machine Learning Algorithms
Artificial Intelligence has two types- Generative AI and Narrow AI. In the same way, Machine learning algorithms have four types. Let’s have a look:
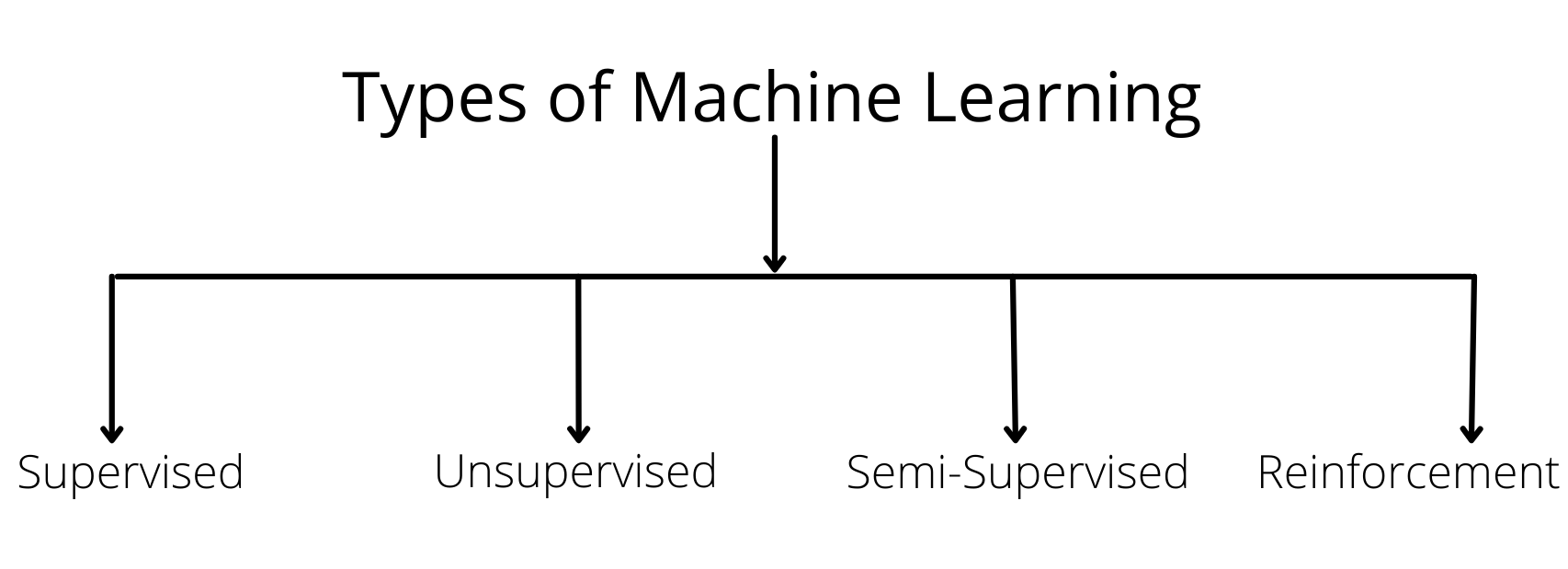
Supervised Learning:
Algorithms learn from labeled data using the machine learning technique known as Supervised Learning. The algorithm receives input data and labels for the associated correct outputs in this procedure. The goal is to teach the algorithm to anticipate labels for brand-new, untainted data correctly.
Let’s have a look at the examples of Supervised Learning algorithms:
- Support vector machines and decision trees
- Random Forests
- Naive Bayes
Unsupervised Learning:
Algorithms analyze unlabeled input in an unsupervised machine learning method without using predetermined output labels. Finding patterns, correlations, or structures within the data is the aim. Unlike Supervised Learning, Unsupervised Learning algorithms operate independently to find hidden ways and combine related data points. Clustering algorithms like this are frequently used in unsupervised learning approaches.
- K-means
- Using a hierarchy to cluster
- Diminished Dimensions techniques such as PCA and t-SNE
Semi-supervised Learning:
A hybrid machine learning technique called Semi-supervised Learning uses labeled and unlabeled data for training. To enhance Learning, it uses a more significant number of unlabeled data and a smaller amount of labeled data. The unlabeled data are supposed to offer more context and knowledge to the model, improving its comprehension and effectiveness. Semi-supervised Learning can overcome the drawbacks of only using labeled data by successfully using unlabeled data. This method is beneficial when getting labeled data requires a lot of money or effort.
Reinforcement Learning:
A machine learning method, Reinforcement Learning, takes its cues from how people learn by making mistakes. Here, an agent interacts with its surroundings and knows to choose wisely to maximize overall rewards. Based on its behaviors, the agent receives feedback through incentives or punishments. Over time, the agent develops the ability to make decisions that result in the best outcomes. Robotics, gaming, and autonomous systems all frequently use it. It makes it possible for machines to use a series of actions to accomplish long-term objectives, adapt to changing environments, and learn from their experiences. Due to its dynamic learning methodology, reinforcement learning is a potent tool for solving challenging decision-making issues.
Also Read Differences Between Artificial Intelligence vs. Machine Learning
Top 10 Machine Learning Algorithms
AI tools and Machine Learning tools are quite popular among the tech-savy users. Let’s explore the top ten Machine Learning algorithms.
Linear Regression:
Linear Regression is a supervised learning algorithm for predicting and forecasting values within a continuous range—for instance, sales figures or home prices. It is a statistical technique frequently applied to determine a relationship between two variables—X and Y—that may be depicted by a straight line. Linear Regression determines the line best fits a set of data points with known input and output values. This curve called the “regression line,” is a forecasting model. Using this line, we can estimate or anticipate the output value (Y) for a given input value (X).
Logistic Regression
The supervised learning approach known as “logistic regression,” commonly referred to as “logistic regression,” is used for binary classification tasks. It is frequently used to decide if an input belongs to one class or another, such as determining whether or not an image depicts a cat. The likelihood that an input may be classified into a single primary class is predicted by logistic regression. The primary class and not the primary class are the two categories most frequently used in practise to group outcomes. Logistic regression establishes a threshold or boundary for binary classification to achieve this. Any output value between 0 and 0.49, for instance, may be put into one group, and any value between 0.50 and 1.00, into the other.
Decision Tree
A supervised learning technique called a decision tree is used for classification and predictive modeling applications. It looks like a flowchart and begins with a root node that poses a particular query on the data. Depending on the response, the data is sent down various branches to succeeding internal nodes, which pose new queries and direct the data to more branches. Until the data reaches an end node, sometimes referred to as a leaf node, where no additional branching occurs, this process continues. Decision tree algorithms have great popularity in the machine learning community as they can handle complex datasets with ease and simplicity.
Read About Super AI: Understanding The Definition, Threats, and Trends

K-means
K-means are frequently used for grouping and pattern recognition applications. Based on how close they are to one another, it attempts to group the data points. K-means uses the idea of proximity to find patterns or clusters in the data, much to K-nearest neighbour (KNN). A centroid, the cluster’s actual or hypothetical centre point, serves to define each of the clusters. K-means can struggle when handling outliers but is excellent for clustering on huge data sets.
By grouping comparable points, K-means is very helpful for huge datasets and can reveal information about the underlying structure of the data. It can be used in a number of different contexts, including customer segmentation, image compression, and anomaly detection.
Apriori
Apriori is an unsupervised learning technique that is utilised in the field of association rule mining, in particular, for predictive modeling. It is frequently used in pattern identification and prediction tasks, such as determining how likely it is that a buyer will buy another product after making a previous purchase.
Transactional data kept in a relational database is analysed by the Apriori algorithm. Frequent itemsets, which are collections of items that frequently appear together in transactions, are identified. Then, association rules are generated using these itemsets. For instance, if customers commonly purchase products A and B together, an association rule suggesting that buying A enhances the likelihood of buying B can be developed.
Support vector machine (SVM)
A common supervised learning approach for classification and predictive modeling problems is the support vector machine (SVM). SVM algorithms are well-liked because they are dependable and effective with little to no data. A “hyperplane” is a decision boundary that is created by SVM algorithms. This hyperplane is comparable to a line dividing two sets of labelled data in two dimensions. By maximising the margin between the two sets of labelled data, SVM seeks to identify the appropriate decision boundary. It searches for the largest separation between the classes. The labels in the training dataset are used to categorise any new data point that lies on either side of this decision boundary.
Gradient boosting
Gradient boosting algorithms use the ensemble method, which produces a number of initial “weak” models that are progressively strengthened to produce a final strong prediction model. The iterative procedure eventually eliminates model errors, resulting in the creation of a final model that is correct and ideal.
The algorithm begins with a straightforward, naive model that could include fundamental presumptions like categorising data according to whether it is above or below the mean. This basic model serves as a foundation. The algorithm creates a new model in each iteration with the goal of fixing the flaws in the preceding models. It recognises the trends or connections that earlier models had trouble capturing and combines them into the new one.
K-nearest neighbor (KNN)
A popular supervised learning technique for classification and predictive modeling problems is K-nearest neighbour (KNN). The term “K-nearest neighbour” describes how the algorithm categorises output depending on how close it is to other data points on a network.
Consider a dataset with points that have been labelled, with some being blue and others being red. KNN considers a new data point’s closest neighbours in the graph when classifying it. The number of nearest neighbours taken into account is indicated by the “K” in KNN. The algorithm examines the five points that are closest to the new data point, for instance, if K is set to 5.
Naive Bayes
A group of supervised learning algorithms known as Naive Bayes are employed to build predictive models for binary or multi-classification tasks. Based on the Bayes Theorem, it uses conditional probabilities to calculate the likelihood of a classification based on a set of combined factors while assuming their independence.
Let’s take a look at a programme that uses the Naive Bayes method to identify plants. In order to classify photos of plants, the system takes into account a number of distinct characteristics, including perceived size, colour, and shape. Although each of these elements is taken into account separately, the algorithm combines them to determine the likelihood that an object is a specific plant.
Random Forest
A group of decision trees used for classification and predictive modeling make up a random forest method. A random forest combines the predictions from various decision trees to provide forecasts that are more accurate than depending solely on one decision tree. In a random forest, a large number (sometimes hundreds or thousands) of decision tree algorithms are separately trained using various random samples from the training dataset. The sample technique is known as “bagging.” Every decision tree is independently trained using its own random sample.
The identical data is sent into each decision tree by the random forest after it has been trained. The random forest totals the outcomes after each tree makes a prediction. The final prediction for the dataset is then chosen from among all the predictions made by the decision trees.
Read More Uses Of Artificial Intelligence For Marketing Analytics
Top Books On Machine Learning Algorithms
Although books give you the knowledge you need to understand things clearly, you still need to have extensive hands-on experience in addition to these books and the relevant materials.
Here is the list of the Top 10 books that we have put together to give you the best information to learn from:
- Introduction to Machine Learning in Plain English for Complete Newbie
- Financial Machine Learning Advances
- Adaptive Computation and Machine Learning series
- Introduction to Machine Learning with Python: A Guide for Data Scientists: Deep Learning with Python
- A Probabilistic View of Machine Learning (Series on Adaptive Computation and Machine Learning)
- Machine Learning: The Complete Beginner’s Guide to Decision Trees, Random Forests, and Neural Networks
- Machine learning and pattern recognition (information science and statistics)
- Scikit-Learn and TensorFlow: Practical Machine Learning with Concepts, Tools, and Techniques to Create Intelligent Systems.
- The Three Building Blocks of Statistical Learning: Prediction, Inference, and Data Mining (Springer Series in Statistics, Second Edition).
Explore The Presence And Menace Of AI In Our Everyday Lives
Endnote
So, now you know the top ten machine learning algorithms. You can study fundamental machine learning principles and techniques from business experts with Machine Learning. Through practical projects and interactive exercises, you can learn how to create and use machine learning models, analyse data, and come to wise judgements. You’ll not only gain competence in using machine learning in numerous fields, but you’ll also perhaps pave the way for intriguing data science employment options.
If you are struggling with the Machine Learning Algorithms, Parangat Technologies are here at your assistance. Contact us today and get a chance to make the most of the advanced technologies and Algorithms

With roll up sleeves, dive in and get the job done approach, it was in the year 2010 when Sahil started Parangat Technologies. Emphasizing a healthy work culture and technology-driven company, he has successfully created a workplace where people love to work and live. He is a software engineer and a passionate blockchain enthusiast.
