The GPT (Generative Pre-trained Transformer) model has revolutionized the field of natural language processing (NLP) by demonstrating remarkable capabilities in generating human-like text. Its ability to understand and generate coherent and contextually relevant responses has made it a go-to tool for various applications, including chatbots, content generation, language translation, and more. While pre-trained versions of GPT are available, building your own GPT model can provide unique advantages and customization options tailored to your specific needs.
Creating your GPT model requires careful planning, domain-specific data, and computational resources. This article will guide you through building your own GPT model, providing actionable advice and insights.
By following the guidelines outlined here, you can unlock the power of GPT and harness its capabilities for your specific use cases. Whether you are an AI enthusiast, a developer, or a researcher, this step-by-step guide will equip you with the knowledge and tools necessary to create your own GPT model.
Now, let’s delve into the components of GPT and explore its benefits!
Overview of the GPT model & its Components)
A GPT (Generative Pre-trained Transformer) model is a state-of-the-art natural language processing (NLP) model that has garnered significant attention and acclaim in recent years. Developed by OpenAI, GPT models are based on the Transformer architecture and have achieved remarkable advancements in language generation and understanding tasks.
At its core, a GPT model consists of two fundamental components: a pre-training phase and a fine-tuning phase.
Pre-training Phase
The GPT model learns from many unlabeled text data during pre-training. This unsupervised learning process involves training the model to predict missing words in sentences, resulting in the model gaining a deep understanding of language structures, context, and semantics. The pre-training phase utilizes a large-scale language modeling task to enable the model to capture the intricacies of human language.
Fine-tuning Phase
After pre-training, the GPT model undergoes a fine-tuning phase using labeled or domain-specific data. This supervised learning approach allows the model to adapt to specific tasks or domains, such as text classification, sentiment analysis, chatbot interactions, or content generation. Fine-tuning tailors the GPT model to perform particular tasks with improved accuracy and relevance.
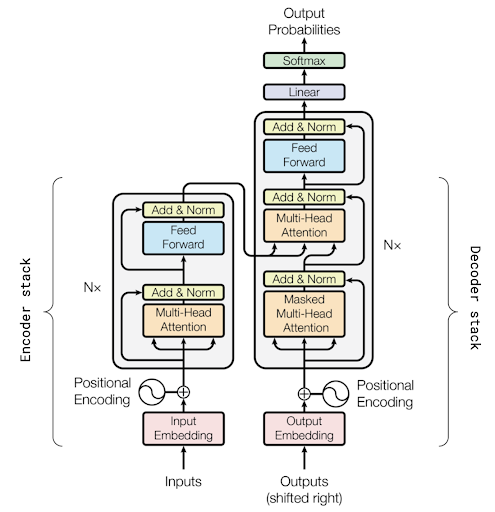
The success of GPT models can be attributed to their attention mechanisms, which enable them to focus on relevant parts of the input text and effectively capture long-range dependencies. With its multi-head self-attention mechanism, the Transformer architecture allows GPT models to handle large-context tasks and generate coherent and contextually relevant responses.
Benefits of Using GPT Models
GPT (Generative Pre-trained Transformer) models offer numerous benefits that have revolutionized the field of natural language processing (NLP) and elevated the quality and efficiency of language generation tasks. Let’s explore some of the key benefits of using GPT models:
Natural Language Generation
GPT models excel in generating human-like text, making them valuable in applications such as chatbots, content generation, and creative writing. By understanding the context and semantics of the input text, GPT models can produce coherent and contextually relevant responses, enhancing the overall user experience.
Versatility and Adaptability
GPT models are highly versatile and adaptable, capable of being fine-tuned for specific tasks and domains. This flexibility enables developers and researchers to leverage the power of GPT models across a wide range of NLP applications, including sentiment analysis, text classification, language translation, and more.
Contextual Understanding
GPT models have a strong grasp of contextual understanding due to their pre-training on vast amounts of unlabeled data. This contextual understanding allows the models to capture the nuances of language and generate responses that align with the given context, resulting in more accurate and meaningful outputs.
Language Creativity
GPT models can generate creative and novel text. With their extensive exposure to diverse language patterns and structures during pre-training, GPT models can generate unique and imaginative responses, making them valuable in creative writing tasks and generating innovative content.
Efficient Content Generation
GPT models can aid in automating content creation processes. By leveraging their language generation capabilities, GPT models can generate high-quality, relevant, and engaging content for various platforms, including articles, product descriptions, social media posts, and more. This efficiency can save time and resources while maintaining the integrity and coherence of the generated content.
Continual Learning and Improvement
GPT models can be further fine-tuned and updated as new labeled data becomes available. This continual learning and improvement process allows the models to adapt to evolving language patterns and stay up-to-date with the latest trends and contexts, ensuring their relevance and accuracy over time.
Learn: AI vs Human Intelligence: What Is the Difference?
Prerequisites to build a GPT model
Before embarking on the journey of building a GPT (Generative Pre-trained Transformer) model, there are several prerequisites that need to be fulfilled. These prerequisites ensure a smooth and successful process. Here are some essential prerequisites to consider:
Domain-specific Data
Collect or curate a substantial amount of domain-specific data that aligns with the desired application or task. A diverse and relevant dataset is crucial for training a GPT model to produce accurate and contextually appropriate responses.
Computational Resources
Building a GPT model requires significant computational resources, particularly in terms of processing power and memory. Ensure access to robust computing infrastructure or consider utilizing cloud-based solutions to handle the computational demands of training and fine-tuning the model.
Data Preprocessing
Prepare the dataset by performing necessary preprocessing steps such as cleaning, tokenization, and encoding. This ensures the data is in a suitable format for training the GPT model.
Training Framework
Choose a suitable deep learning framework, such as TensorFlow or PyTorch, to facilitate the implementation and training of the GPT model. Please familiarize yourself with the chosen framework’s documentation and APIs to efficiently utilize its functionalities.
GPU Acceleration
Utilize GPU acceleration to expedite the training process. GPT models, with their large-scale architecture, benefit greatly from parallel processing provided by GPUs, significantly reducing training times.
Fine-tuning Strategy
Define a fine-tuning strategy to adapt the pre-trained GPT model to your specific task or domain. Determine the appropriate dataset for fine-tuning and establish the parameters and hyperparameters required for achieving optimal performance.
Evaluation Metrics
Select appropriate evaluation metrics that align with the desired performance goals of your GPT model. Common metrics include perplexity, BLEU score, or custom domain-specific metrics that measure the quality and coherence of the generated text.
Expertise in Deep Learning
Acquire a solid understanding of deep learning concepts, specifically related to sequence-to-sequence models, attention mechanisms, and transformer architectures. Please familiarize yourself with the principles underlying GPT models to effectively build and fine-tune them.
Version Control and Experiment Tracking
Implement a version control system and experiment tracking mechanism to manage iterations, track changes, and maintain a record of configurations, hyperparameters, and experimental results.
Patience and Iteration
Building a high-quality GPT model requires patience and iteration. Experiment with different architectures, hyperparameters, and training strategies to achieve the desired performance. Continuous experimentation, evaluation, and refinement are crucial for optimizing the model’s performance.
Related: What are the Advantages of ChatGPT?
How are GPT Models Created?
Creating a GPT (Generative Pre-trained Transformer) model involves a series of steps that encompass data collection, preprocessing, architecture selection, pre-training, fine-tuning, iterative optimization, and deployment. Let’s explore each of these steps in detail:
Data Collection
The first step in building a GPT model is collecting or curating a large corpus of text data relevant to the target domain or task. The dataset should be diverse and representative to ensure the model learns a broad range of language patterns and contexts.
Preprocessing
Once the dataset is collected, preprocessing is performed to clean the data and transform it into a suitable format for training. Preprocessing typically involves removing noise, handling punctuation, tokenizing the text into individual words or subwords, and encoding the data for input into the model.
Architecture Selection
Choosing the appropriate architecture is crucial for building an effective GPT model. With its attention mechanism and self-attention layers, the Transformer architecture is commonly used for GPT models due to its ability to capture long-range dependencies and contextual information effectively.
Pre-training
Pre-training is a crucial phase where the GPT model is trained on a large corpus of unlabeled text data. The model learns to predict missing words or tokens in sentences, acquiring an understanding of language structures, context, and semantics. Pre-training is typically performed using unsupervised learning techniques, such as the masked language modeling objective.
Fine-tuning
After pre-training, the GPT model is fine-tuned on a smaller dataset that is labeled or specific to the desired task or domain. Fine-tuning allows the model to adapt its knowledge to the target task, improving performance and relevance. Fine-tuning involves training the model using supervised learning techniques, often with a task-specific objective or loss function.
Iterative Optimization
Building a GPT model involves iteration and experimentation. Various hyperparameters, architectures, and training strategies are explored and refined to optimize the model’s performance. Evaluation metrics, such as perplexity or task-specific, are used to assess and compare different model iterations.
Deployment and Usage
Once the GPT model is trained and optimized, it can be used in real-world applications. Deployment involves integrating the model into the desired system or platform, providing an interface for users to interact with the model’s language generation capabilities. The deployed model can generate responses, suggestions, or outputs based on the specific task it has been trained for.
You might be interested in: Integrating ChatGPT with Mendix: All you Need to Know
Considerations While Building a GPT Model
Building a GPT (Generative Pre-trained Transformer) model requires careful consideration of several important aspects to enhance its performance, mitigate potential issues, and ensure responsible and effective language generation. Here are some key considerations to keep in mind:
1. Removing Bias and Toxicity
Bias and toxicity are critical concerns in language generation models. Take steps to identify and mitigate biases in the training data to prevent the model from perpetuating or amplifying harmful biases. Implement techniques such as debiasing algorithms, diverse training data, and fine-tuning with fairness objectives to address bias. Additionally, employ content filtering and moderation mechanisms to reduce the generation of harmful or inappropriate content.
2. Improving Hallucination
Hallucination refers to situations where the model generates incorrect or fictional information. Addressing hallucination involves training the GPT model on high-quality and reliable data sources, incorporating fact-checking mechanisms, and utilizing external knowledge bases or fact repositories to verify generated information. Iterative refinement and continuous evaluation can help improve the model’s accuracy and reduce hallucinations.
3. Preventing Data Leakage
Data leakage occurs when the GPT model inadvertently memorizes and regurgitates parts of the training data, potentially leading to privacy concerns or unintentional disclosure of sensitive information. Apply techniques such as token masking during pre-training, careful dataset selection, and data sanitization to mitigate the risk of data leakage and preserve privacy.
4. Incorporating Queries and Actions
To make GPT models more interactive and task-oriented, consider incorporating queries and actions as part of the language generation process. This involves modifying the model architecture or introducing additional input mechanisms that allow users to provide specific instructions or prompts, guiding the generated responses toward desired outcomes. Design the model to understand and respond effectively to user queries and actions.
Build Your Custom GPT Model
In this comprehensive guide, we have explored creating a customized GPT (Generative Pre-trained Transformer) model. We have delved into each step, from data collection to preprocessing, architecture selection, pre-training, fine-tuning, and iterative optimization. We discussed considerations such as removing bias and toxicity, improving hallucination, preventing data leakage, and incorporating queries and actions.
By following these guidelines and harnessing the power of GPT models, you can embark on an exciting journey of language generation. Build a GPT model that generates natural, contextually relevant, and responsible text for various applications. Remember to continuously evaluate and refine your model to ensure its performance, mitigate biases, and align with ethical considerations.
As you progress in your GPT model-building endeavors, remember the importance of using actionable advice, maintaining readability, backing up claims with reputable sources, and providing unique insights. With the right approach and adherence to best practices, your custom GPT model can unlock new possibilities in language generation and empower you to impact your field significantly.
Are you looking for GPT developers to build your custom GPT model? Reach out to Parangat!






